Github Action + Vercel 实现静态站点友链朋友圈




使用 Github Action 爬取友链数据,使用 Vercel 函数查询友链数据,并且所有服务都是免费的,白嫖党的福音。
闲着没事穿越博客,点了好几个都有友联朋友圈什么的,然后就点到了 Friend-Circle-Lite,还挺有意思的,我也搞下。
最需要一个免费的数据库,用于存储临时数据。
使用 TIDBtidbcloud.com/,有一定量的免费额度。小打小闹够用。
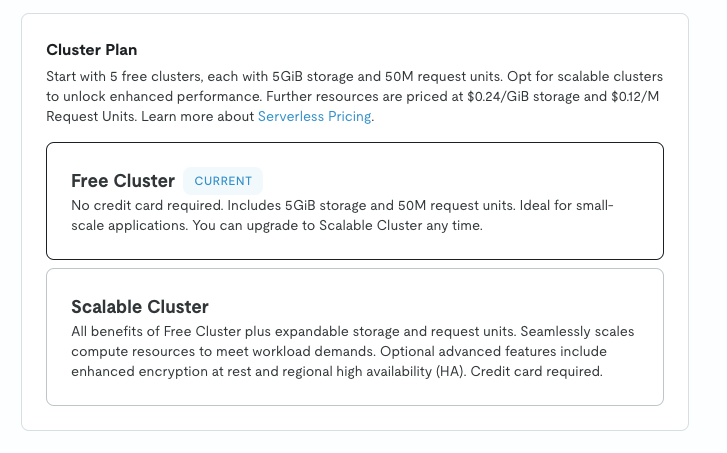
也可以使用 MongoDB
MongoDB Atlas 是 MongoDB Inc 提供的 MongoDB 数据库托管服务。免费账户可以永久使用 500 MiB 的数据库。这个注册可以参考:twikoo.js.org/mongodb-atlas.html
准备 friend.json
既然利用了 github 那么大概率使用的静态博客。所以先需要友联的数据,可以整理成如下格式:
[
{
"name": "xxx",
"link": "xxx",
"avatar": "xxx",
"desc": "xxx",
"rss": "xxx"
}
]
我使用的静态博客,并且友联数据用的 excel 文件,那么整理成上面的数据可以参考:
const XLSX = require('xlsx');
const fs = require('fs');
// 读取现有的 Excel 文件
const workbook = XLSX.readFile('data/Friends.xlsx');
// 获取工作表名称列表
const sheetNames = workbook.SheetNames;
// 获取工作表
const worksheet = workbook.Sheets[workbook.SheetNames[0]];
const data = XLSX.utils.sheet_to_json(worksheet);
// 结果写入json 文件
fs.writeFile('data/friend_info.json', JSON.stringify(data, null, 2), err => {
if (err) {
console.error(`Error writing file: ${err}`);
} else {
console.log('Commit statistics written to commitStats.json');
}
});
解析脚本(python)
接下来就需要一个脚本来解析友联,得到 RSS 地址,再得到 RSS 数据解析,最后存储。这里我使用的 python 脚本相比于其他的更简单。
脚本内容如下:
import mysql.connector
from mysql.connector import Error
import json
import feedparser
from datetime import datetime
import time
import sys
db_name = "friend"
post_table_name = "friend_post"
articles = []
# 接收参数
if len(sys.argv) < 3:
print("❌用法:python 脚本.py 参数1 参数2")
sys.exit(1)
username = sys.argv[1]
password = sys.argv[2]
# 解析friend.json 文件
try:
with open('./data/friend_info.json', 'r', encoding='utf-8') as file:
data = json.load(file)
for item in data:
if item.get("rss"):
# 解析RSS
feed = feedparser.parse(item["rss"])
# 遍历文章,取前两条
for entry in feed.entries[:2]:
updated_time = time.strftime("%Y-%m-%d %H:%M:%S",
time.struct_time(entry.updated_parsed))
entry_data = {
"site": item['name'],
"avatar": item['avatar'],
"title": entry.title,
"link": entry.link,
"date": updated_time,
"date_timestamp": int(datetime.strptime(updated_time, "%Y-%m-%d %H:%M:%S").timestamp())
}
articles.append(entry_data)
print(f"✅ 文章RSS已解析完毕!: {item['name']}")
# 按照时间戳倒序排序
articles = sorted(
articles, key=lambda x: x['date_timestamp'], reverse=True)
except Exception as e:
print(f"未知错误:{type(e).__name__} - {str(e)}")
sys.exit(1)
# 如果articles为空,打印日志,并结束
if not articles:
print("❌ 没有获取到文章!")
sys.exit(1)
# 结果写入 MYSQL
try:
conn = mysql.connector.connect(
host="gateway01.ap-northeast-1.prod.aws.tidbcloud.com",
port=4000,
user=username,
password=password,
database=db_name,
)
if conn.is_connected():
print(f"✅ 成功连接MySQL版本:{conn.server_info}")
cursor = conn.cursor()
# 清空表(DELETE)
cursor.execute("DELETE FROM "+post_table_name)
conn.commit()
print(f"✅ 表已清空(DELETE),影响行数:{cursor.rowcount}")
sql = """
INSERT INTO friend_post (site, avatar, title, link, date, date_timestamp)
VALUES (%(site)s, %(avatar)s, %(title)s, %(link)s, %(date)s, %(date_timestamp)s)
"""
# 批量插入数据
cursor.executemany(sql, articles)
conn.commit()
print(f"✅ 成功插入 {cursor.rowcount} 条记录")
except Error as e:
print(f"❌ 连接失败: {e}")
finally:
if 'cursor' in locals() and cursor:
cursor.close()
if conn.is_connected():
cursor.close()
conn.close()
print("🔌 连接已关闭")
脚本的话首先读取 json 文件,然后解析后,再存储到 tidb 数据库中。 如果本地测试的话,可以:
python collect_post.py 数据库用户名 数据库密码
需要的主要依赖
feedparser==6.0.11
mysql-connector-python==9.3.0
你可以把脚本和依赖文件放在同一个文件夹内,方便使用。比如都放在 python 文件夹内。
./python
├── friend
│ ├── collect_post.py
│ └── requirements.txt
连接 TIDB 数据库
TIDB 数据库几乎和 mysql 使用的方式一样。
在控制台上方点击 Connect to your app

然后选择你使用的开发工具,就可以得到连接信息。
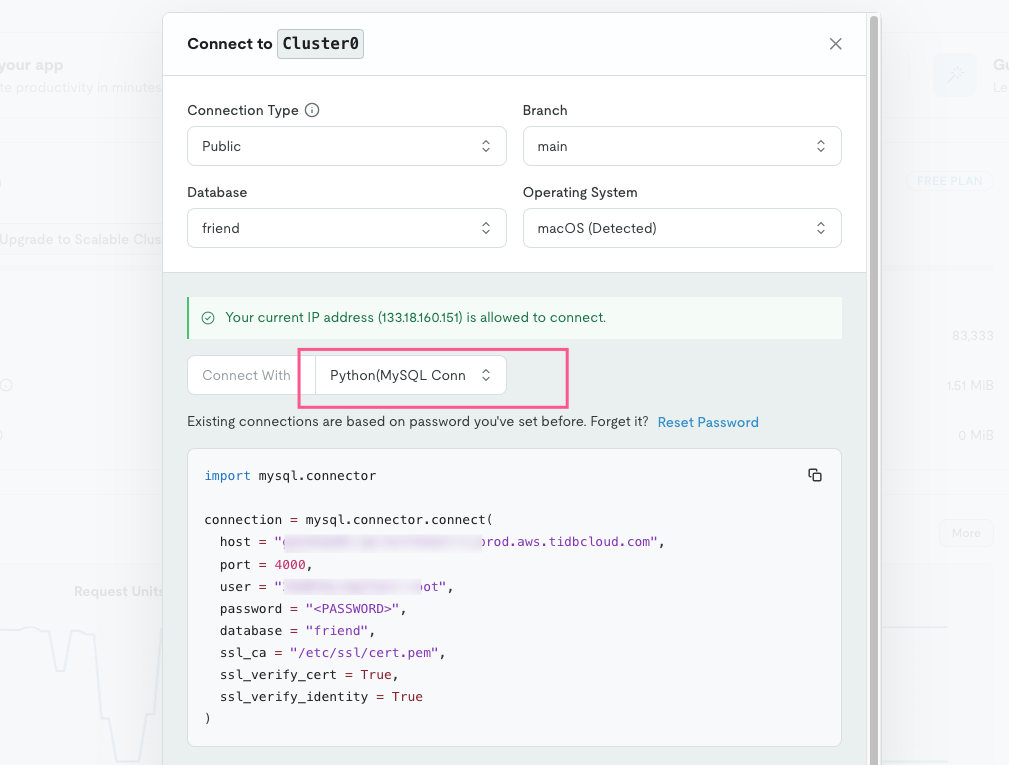
同理,利用上面的连接信息,你也可以在本地的数据库工具连接,比如 navicat:
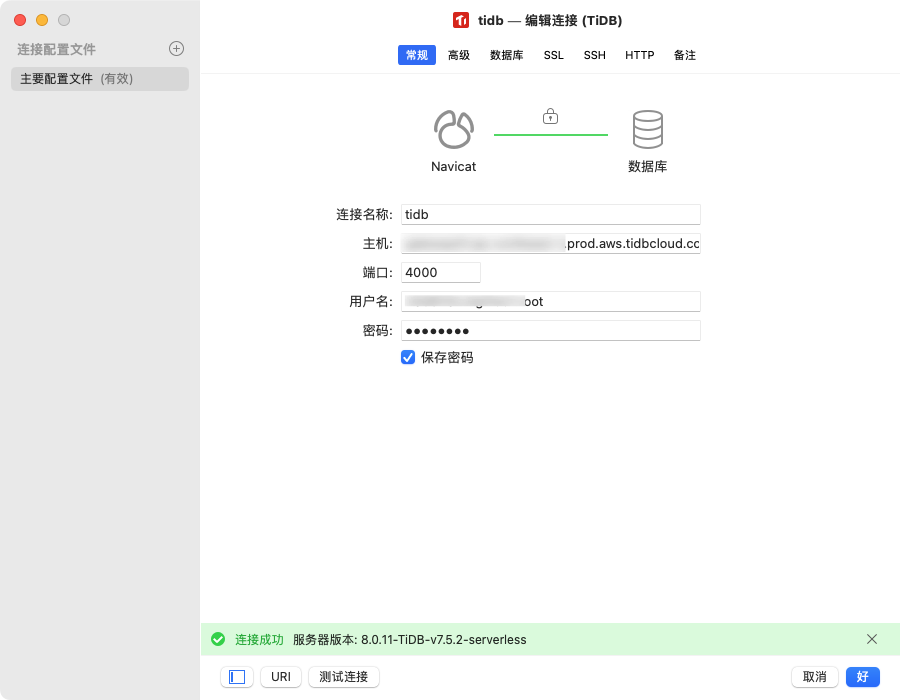
注意:需要开启 SSL 才能连接上!
连接上数据库后,那么新建个数据库,添加个表来存储我们的数据。
DROP TABLE IF EXISTS `friend_post`;
CREATE TABLE `friend_post` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`site` varchar(128) DEFAULT NULL,
`avatar` varchar(128) DEFAULT NULL,
`title` varchar(128) DEFAULT NULL,
`link` varchar(255) DEFAULT NULL,
`date` varchar(32) DEFAULT NULL,
`date_timestamp` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET=utf8mb4;
创建 workflow
在 .github/workfolw 目录下新建 abc.yml 名称随意。
脚本内容参考:
# 采集 RSS 数据
name: collect-friend-posts
on:
schedule:
# GitHub Actions 使用的是 UTC 时间,如果你想要在中国时区(UTC+8)每天凌晨2点执行任务,你需要设置为 UTC 时间的前一天的 18:00(下午 6 点)。
- cron: 0 */3 * * *
# 下面的配置为手动触发
# workflow_dispatch:
jobs:
parse-rss-and-store:
runs-on: ubuntu-latest # 在最新版本的 Ubuntu 操作系统环境下运行
steps: # 要执行的步骤
- name: Checkout code
uses: actions/checkout@v3 # 用于将github代码仓库的代码拷贝到工作目录中
- name: Set up Python
uses: actions/setup-python@v2 # 用于设置 Python 环境,它允许你指定要在工作环境中使用的 Python 版本
with:
python-version: '3.9' # 选择要用的Python版本
- name: Install requirements.txt
run: | # 安装依赖包
pip install -r ./python/friend/requirements.txt
- name: Run main.python
run: python ./python/friend/collect_post.py ${{ secrets.TIDB_USER }} ${{ secrets.TIDB_PASSWORD }}
因为数据库的连接信息属于敏感信息,所以建议放到仓库的 Actions secrets and variables
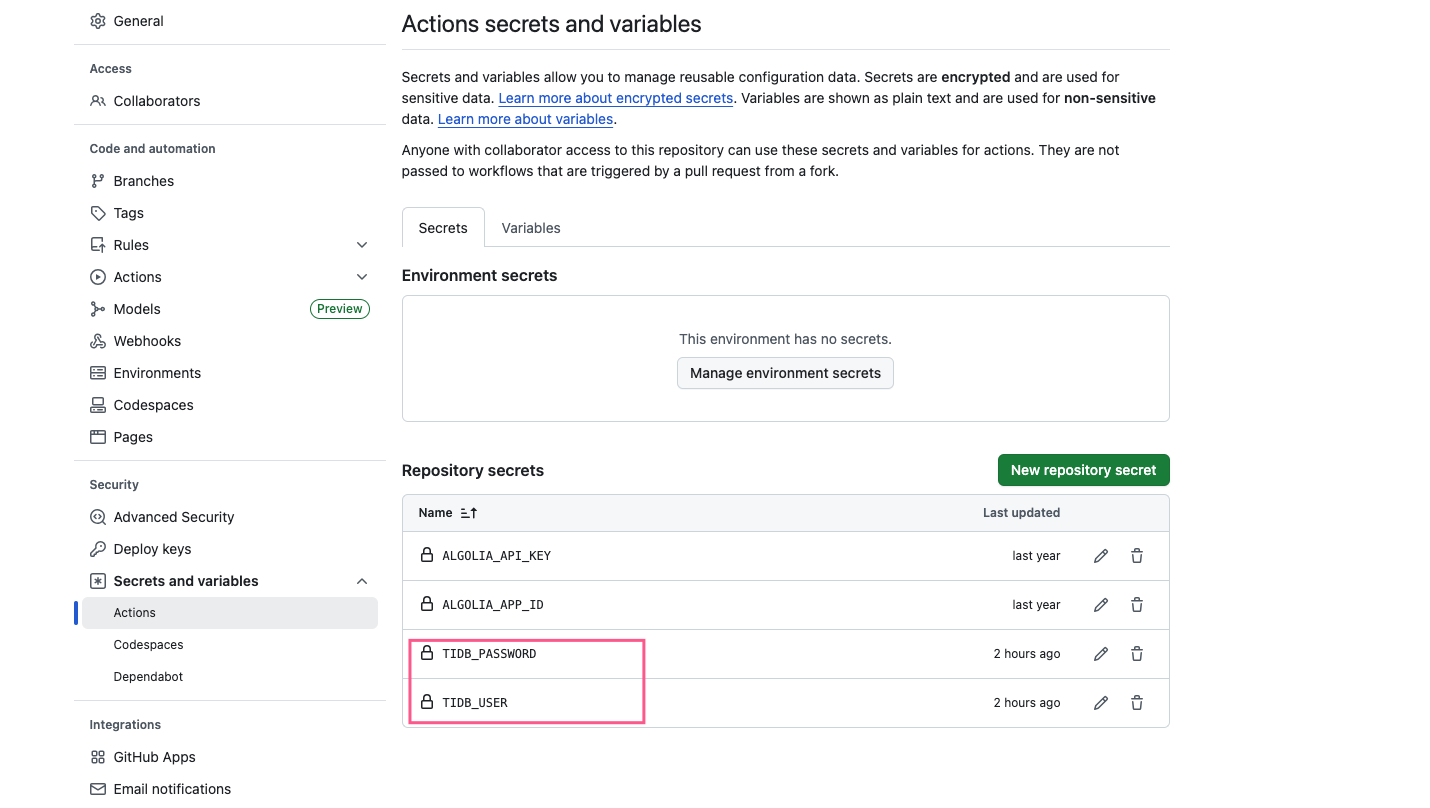
然后直接提交代码即可。
测试流水线
如果你想测试下流水线下,可以把配置文件中的触发机制从定时执行修改为手动触发。
# 采集 RSS 数据
name: collect-friend-posts
on:
workflow_dispatch:
这样在仓库的 Actions 中这条流水线右侧就有一个执行按钮,手动执行即可,测试完毕再修改为定时触发就好拉。
查询友联文章
上面的步骤已经到友联的文章搞到数据库中了,接下来需要解决下,如果想要再静态博客中使用,如何查询这些数据。
这个时候就想到 Serverless Funtion,各大厂商都有在搞这个。
这其中我感觉最简单的是 vervel 服务。有一定免费额度,部署起来相对简单。Vercel 部署个 Serverless 函数
我们的需求很简单,python 连接数据库,分页查询数据返回 json 结果即可。
示例代码:
你需要将 tidb 用户名和密码放在环境变量中。
# 查询友链文章
@app.route('/friend/posts/<int:page_no>/<int:page_size>')
def friend_posts(page_no, page_size):
try:
conn = mysql.connector.connect(
host="gateway01.ap-northeast-1.prod.aws.tidbcloud.com",
port=4000,
user=os.environ["TIDB_USER"],
password=os.environ["TIDB_PASSWORD"],
database="friend",
)
if conn.is_connected():
print(f"✅ 成功连接MySQL版本:{conn.server_info}")
cursor = conn.cursor(dictionary=True)
# 分页参数
offset = (page_no - 1) * page_size
# 执行分页查询
query = "SELECT * FROM friend_post ORDER BY date_timestamp desc LIMIT %s OFFSET %s"
cursor.execute(query, (page_size, offset))
results = cursor.fetchall()
# 获取总记录数(用于分页元数据)
cursor.execute("SELECT COUNT(*) AS total FROM friend_post")
total_records = cursor.fetchone()['total']
response = {
"message": "数据获取成功",
"data": results,
"pagination": {
"current_page": page_no,
"per_page": page_size,
"total_items": total_records,
"total_pages": int(total_records / page_size + 1)
}
}
return jsonify(response)
except Error as e:
print(f"❌ 连接失败: {e}")
finally:
if 'cursor' in locals() and cursor:
cursor.close()
if conn.is_connected():
cursor.close()
conn.close()
print("🔌 连接已关闭")
return jsonify({})
完结撒花 🎉🎉
这样从爬取到查询就都有了~,示例:友链朋友圈,除了加载有点慢以外,别的没毛病!😄